Back in college, I spent a semester trying to teach a neural network to color old black-and-white photos. The premise sounds romantic: feed in a grayscale photo of someone’s grandparents, get back a plausible color version. The reality was a lot of late nights staring at outputs that looked like someone had spilled weak tea over everything.
However, if you train a model the obvious and seemingly-reasonable way - showing it a grayscale photo, asking it to guess the colors, and penalizing based on how far the guess is from the truth, pixel by pixel, you get a down-right average outcome.
A sky could be blue, or orange at sunset, or grey and overcast. When the model isn’t sure, the mathematically safe move is to hedge and pick something in the middle of all the plausible options. And the middle of “blue, orange, grey” is a muddy brown sludge.
So my model learned to be a coward. It colored everything in timid sepia because timid was the lowest-risk way to not be too wrong. Technically optimal. Completely useless.
So what the hell is a GAN?
What saved me and was also one of the most useful ideas I’ve learnt back in college for machine learning is, instead of having one network trying to do everything, use two and make them enemies.
Imagine a forger and an art detective. The forger’s job is to produce fakes good enough to pass as real, and in my case the “forger” was a network that painted colors onto a grayscale photo. The detective’s job is the opposite: a second, separate network whose only skill was answering one question, “was this colored by a real human, or by that other network over there?”
Thehe beautiful part is you train them against each other in a self-improvement loop. Early on the detective spots the fakes easily because the forger is terrible (remember the tea stains). Every time the detective catches a fake, that’s a signal the forger uses to get a little better. Every time the forger slips one past, the detective sharpens its eye. Round after round, each one drags the other upward.
This setup is called a Generative Adversarial Network, or GAN, introduced by Ian Goodfellow and his collaborators in 2014. The forger wins when it fools the detective, the detective wins when it catches the forger, and neither is allowed to get comfortable. And the muddy-sepia problem? Gone. Timid brown is exactly what a detective spots in a heartbeat, so to survive, the forger had to commit. Bold blue skies, proper green grass - all thanks to its “mean” counterpart.
The pattern that stuck around
My colorizer was never going to win any awards (ML folks, please spare my mistakes, this was a student project held together with hope). But the lesson outlasted the project:
I didn’t need a perfect way to measure quality. I needed a good adversary.
Writing down a formula for “is this a good coloring” is borderline impossible. Beauty, plausibility, the way a real photo just feels right, none of that fits in an equation. But “can another network tell this apart from a real photo?” is a question you can answer, and chasing it turned out to be a brilliant proxy for everything I couldn’t write down. A doer and a skeptic, each specialized, beat one network trying to be both. I reckon that division of labor is the real magic, more than any particular architecture.
Hold onto that, because it’s about to come back in a very different costume.
Then models became a commodity
Just like how cloud computing took racks of servers and a room full of blinking lights and turned them into a metered API you rent by the hour, foundation models have done the same to “a trained neural network.” I used to build my generator: design its layers, gather a dataset, run the training, fix the training when it collapsed, run it again. That generator was a thing I made.
Today? I don’t build the generator. I open a chat window. The capability that used to need a research lab, a GPU cluster, and a very patient graduate student now sits one prompt away from anyone with an internet connection. The generator stopped being something you build and became something you rent.
So the natural question is: if the model does everything now, what’s left of all those clever techniques from the old days? More than you’d think.
The adversarial idea didn’t die, it moved up a layer
The adversarial trick from my college project didn’t become obsolete when models got commoditized. It just moved up a level of abstraction.
Back then, the forger and the detective were two different networks I had to build and train. Today they can both be the same commodity model wearing different hats. The exact same Claude that drafts an answer can, in a separate breath, put on a skeptic’s coat and tear that answer apart. People call it “LLM-as-judge” when a model grades another’s output, a generator-critic loop when one pass produces and another refutes, red-teaming when an agent’s whole job is to break your system. It’s the forger and the detective all the way down.
The one detail that matters most, the same one that mattered in my GAN: the critic has to be separate. Back then that was literal, two distinct networks. Today the equivalent is fresh context. If you ask the same chat session that just wrote something to also critique it, it’s not a neutral judge: it knows why it made every choice and it’ll wave its own work through. The critic only works if it comes in cold, judging the artifact rather than the intent. Same principle, new substrate.
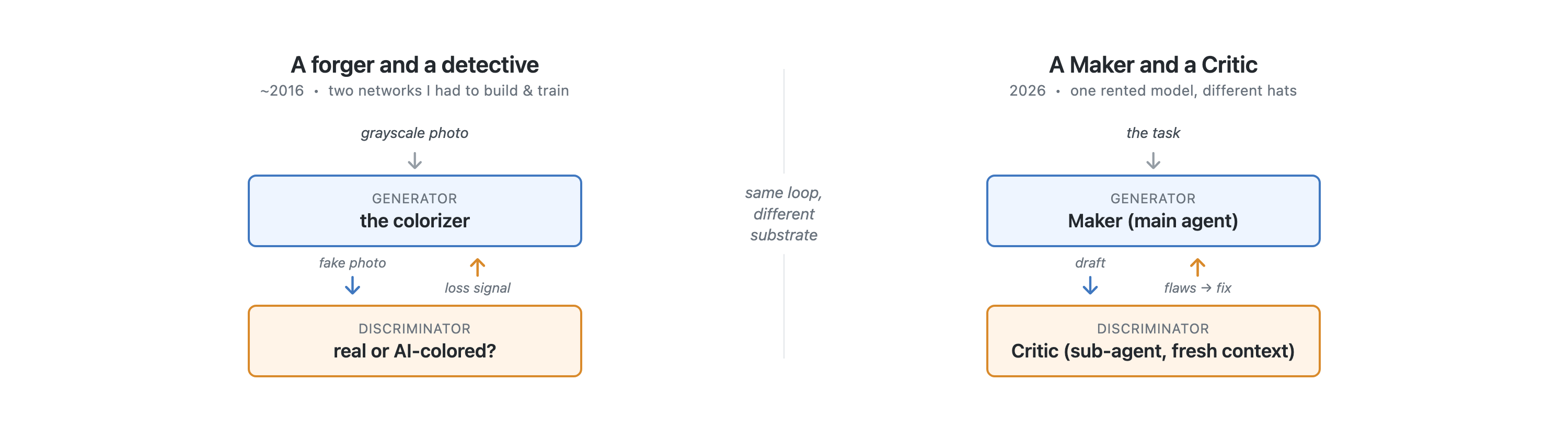
Same loop, different substrate. Ten years ago the forger and detective were two networks I had to build and train. Today they’re one rented model wearing different hats.
You can do this today without writing a line of code
Now we get to the part I’m excited about, because you don’t need to be doing machine learning to use any of this. If you’ve used Claude Code or Claude Cowork, you’ve already got everything you need. The modern version of my forger-and-detective setup isn’t two browser tabs you babysit. It’s a sub-agent workflow you set up once.
The Maker is the generator, the main agent doing the actual work, writing the code, drafting the analysis, building the deck. The Critic is the detective: instead of trusting the Maker to grade its own homework, the main agent spawns a sub-agent in its own fresh context whose only job is to find everything wrong. That’s the same separation that made my detective a different network.
Wiring it up is a single instruction to your main agent:
Work on this task in an adversarial loop.
1. Draft a solution (you are the Maker).
2. Spawn a sub-agent as a hostile Critic: "Find every unsupported claim,
weak step, and bug. Return a numbered list of flaws, or PASS if you
genuinely can't break it." Give it only the output, not your reasoning.
3. Fix every valid flaw, then spawn a NEW Critic on the revised version.
4. Repeat until the Critic returns PASS or you hit 4 rounds.
That’s it: a doer and a skeptic locked in a feedback loop. If you’re a developer you’ve already seen a version of this, since that’s essentially what /code-review and /security-review do under the hood. You can even hand the whole loop to Claude Code’s /goal command (something like /goal the hostile critic returns PASS) and let it keep iterating on its own until the condition holds, which is delightful because /goal leans on a separate model to judge whether you’re done, so the “make the judge separate” rule sneaks in one more layer up the stack. The thing that used to take me two custom networks and a week of fighting unstable training is now a couple of roles played by one rented model, spun up in the time it takes to write a paragraph.
The Good, the Bad, and the Brittle
A critic is not a truth oracle. Research into LLM-as-judge setups keeps finding these critics are fragile and gameable: certain trigger phrases inflate a judge’s scores, and a determined generator can learn to flatter its judge instead of improving. A detective that can be sweet-talked is worse than none, because it gives you false confidence.
Don’t put an expensive critic everywhere either. Spawning a skeptic on every trivial step gets slow and pricey, and nitpicking small stuff drowns out the flaws that matter. Save the adversarial loop for work where being wrong costs you something.
And for real robustness, borrow from how teams red-team today (tools like Microsoft’s PyRIT exist for this): use a panel of diverse critics rather than one. One looks for security holes, another for logical gaps, another for factual grounding. Just like how my detective could only catch the kinds of fakes it had learned to recognize, one critic only catches the mistakes it’s looking for.
Same idea, a tenth of the price
Ten years ago, putting a forger and a detective in a room together meant two bespoke networks, a GPU that sounded like a jet engine, and a week of coaxing the training to not collapse into garbage. Today that same idea is a main agent, a critic sub-agent, and one stubborn instruction. The architecture got commoditized, but the idea, that pitting a maker against an honest skeptic gets you somewhere neither reaches alone, didn’t get cheaper to the point of irrelevance. It got cheaper to the point of being available to everyone.
Some tl;dr key takeaways:
- You often don’t need a perfect way to measure quality, you need a good adversary.
- The critic has to be separate (a fresh context, a spawned sub-agent), or it just rubber-stamps its own work.
- Commodity models didn’t kill the adversarial trick, they turned it from a research project into a prompt.
- Critics are gameable, so use them where it matters and prefer a diverse panel over a single judge.
So next time you’ve got an agent doing something important, don’t just take its first answer. Give it an opponent. The forger always paints better when there’s a detective in the room. 🕵️